How to Convert a Parquet File to CSV | [Answered]
Parquet is a popular columnar storage file format used in data processing frameworks like Apache Hadoop and Apache Spark. It is efficient for both storage and processing, especially for large datasets.
However, sometimes you might need to convert Parquet files to CSV format for compatibility with other tools or for data exchange purposes. This article will guide you through the process of converting a Parquet file to a CSV file using various methods, including Python libraries.
Why Convert Parquet to CSV?
Converting a parquet file to CSV can be a necessity due to the reasons below.
Compatibility: While Parquet is highly efficient, not all data processing tools support it. CSV, on the other hand, is universally supported.
Simplicity: CSV files are human-readable and can be easily viewed and edited with simple text editors or spreadsheet applications.
Data Sharing: CSV is a common format for data exchange, making it easier to share data with others who might not have tools to read Parquet files.
How Do I Convert a Parquet File to CSV?
In this section, we will discuss three proven methods to convert a parquet file to CSV.
Method 1: How to Convert Parquet File to CSV in Python
Pandas is a powerful data manipulation library in Python that can read and write data in many formats, including Parquet and CSV.
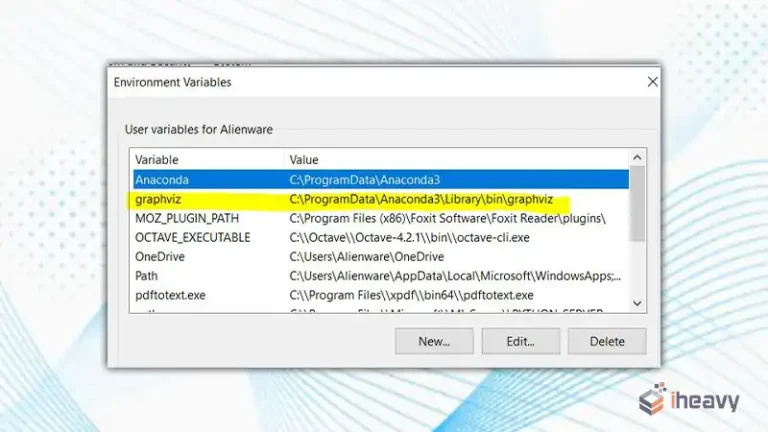
1. Install Required Libraries: Ensure you have Pandas and PyArrow installed. You can install them using pip:
pip install pandas pyarrow
2. Convert Parquet to CSV: Here’s a simple script to convert a Parquet file to CSV using Pandas:
import pandas as pd
# Read the Parquet file
df = pd.read_parquet('input_file.parquet')
# Write to a CSV file
df.to_csv('output_file.csv', index=False)Method 2: Using PySpark
PySpark, the Python API for Apache Spark, can also be used to convert Parquet files to CSV. This method is suitable for handling large datasets.
1. Install PySpark: You can install PySpark using pip:
pip install pyspark
2. Convert Parquet to CSV: Use the following script to convert a Parquet file to CSV with PySpark:
from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName('ParquetToCSV').getOrCreate()
# Read the Parquet file
df = spark.read.parquet('input_file.parquet')
# Write to a CSV file
df.write.csv('output_directory', header=True)Note that PySpark writes the CSV file to a directory. Each partition will be written to a separate CSV file within this directory.
Method 3: Using Apache Drill
Apache Drill is a schema-free SQL query engine that supports a variety of data sources and formats, including Parquet and CSV.
1. Start Apache Drill: Ensure you have Apache Drill installed and running.
2. Convert Parquet to CSV: You can execute a SQL query to convert Parquet to CSV:
SELECT * FROM dfs.`/path/to/input_file.parquet`
WHERE ...
STORE AS `csv` LOCATION '/path/to/output_directory';Frequently Asked Questions
Can I open a Parquet file in Excel?
Spreadsheet applications such as Microsoft Excel and Google Sheets do not have built-in support for the Parquet file format. To work with a Parquet file in Excel, you need to first convert it to a CSV or XLSX format.
What app opens Parquet files?
Parquet Viewer is a quick and user-friendly tool for reading Parquet files. It allows you to open and view Parquet files directly on your computer. There are other tools as well.
Can we query Parquet files?
You can query Parquet files just as you would read CSV files. The main difference is setting the FILEFORMAT parameter to PARQUET.
Conclusion
By following the steps outlined above, you can easily convert Parquet files to CSV. Whether you choose Pandas, PySpark, or Apache Drill depends on your specific needs and the size of your dataset. While Pandas is ideal for small to medium datasets, PySpark is suited for large datasets and distributed computing.