Data Partitioning and Sharding in MySQL
As databases grow in size and complexity, managing data efficiently becomes crucial. Two common strategies used to enhance database performance and scalability are data partitioning and sharding.
While they might seem similar, they serve different purposes and are implemented in distinct ways. This article analyzes the concepts of data partitioning and sharding in MySQL, explaining how each works, their benefits, and when to use them.
What Is Data Partitioning in MySQL?
Data partitioning is the process of dividing a single database table into smaller, more manageable pieces called partitions. Each partition is stored and accessed separately but is still part of the same logical table. This approach can significantly improve query performance and manageability for large datasets.
Types of Data Partitioning in MySQL
MySQL offers several partitioning strategies to optimize database performance and management based on specific data characteristics and query patterns.
1. Range Partitioning
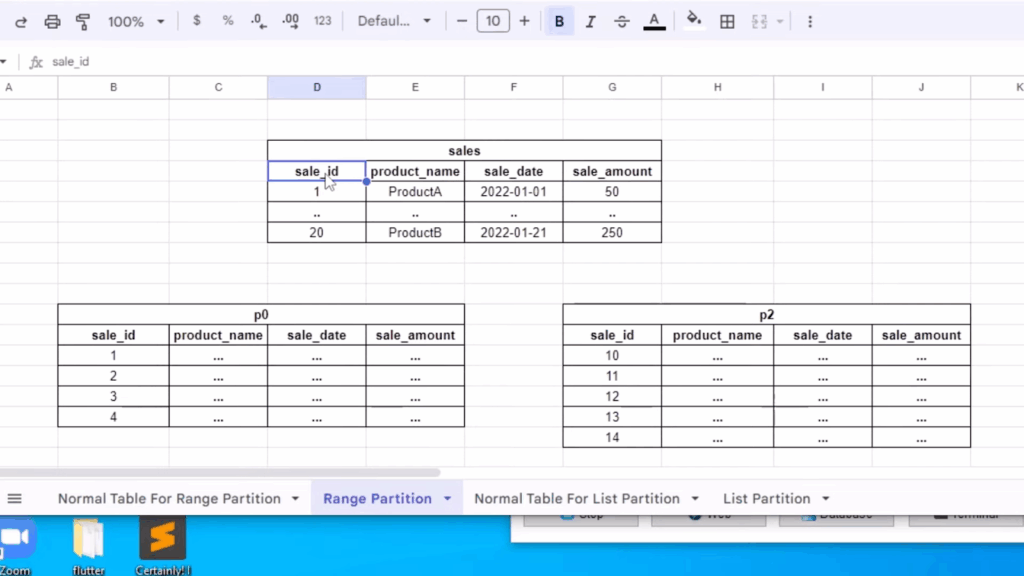
In range partitioning, rows are assigned to partitions based on column values that fall within a specified range. For instance, a table could be partitioned by date, with each partition representing a month or a year.
Example:
-- Create a table named 'sales' with three columns:
-- - id: an integer column to uniquely identify each sale
-- - sale_date: a date column representing the date of the sale
-- - amount: a decimal column with 10 digits and 2 decimal places for the sale amount
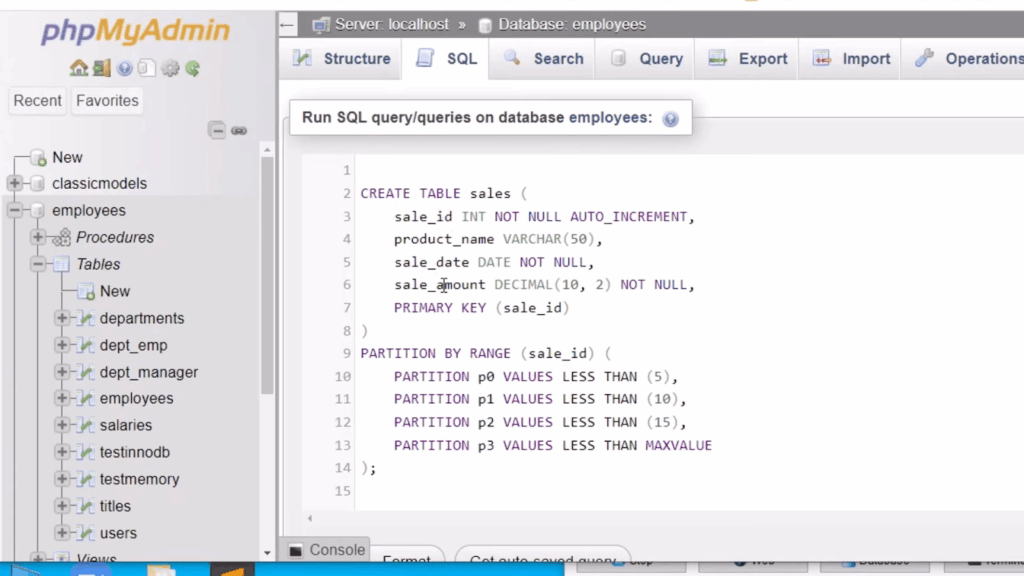
CREATE TABLE sales (
id INT,
sale_date DATE,
amount DECIMAL(10, 2)
)
-- Partition the table by the year of the sale_date column
-- This improves query performance by separating data into different partitions
PARTITION BY RANGE (YEAR(sale_date)) (
-- Partition for sales in the year 2021
PARTITION p2021 VALUES LESS THAN (2022),
-- Partition for sales in the year 2022
PARTITION p2022 VALUES LESS THAN (2023),
-- Partition for sales in the year 2023
PARTITION p2023 VALUES LESS THAN (2024)
);
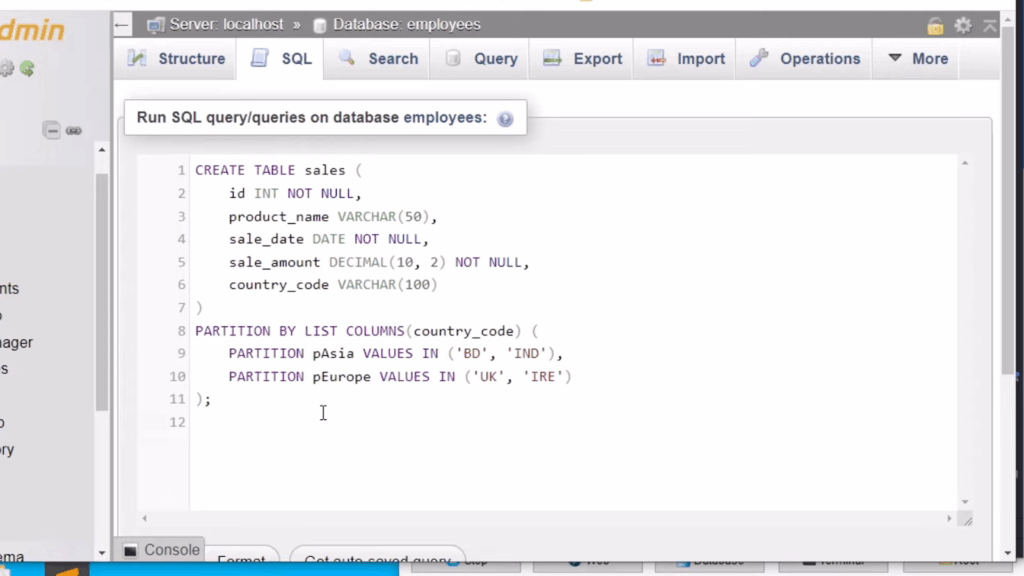
2. List Partitioning
List partitioning is similar to range partitioning but uses a list of discrete values to define each partition. It’s useful when data needs to be separated into non-continuous categories.
Example:
-- Create a table named 'employees' with three columns:
-- - id: an integer column to uniquely identify each employee
-- - name: a varchar column with a maximum length of 100 characters for the employee's name
-- - department: a varchar column with a maximum length of 50 characters for the employee's department
CREATE TABLE employees (
id INT,
name VARCHAR(100),
department VARCHAR(50)
)
-- Partition the table by the 'department' column
-- This improves query performance by separating data into different partitions based on department
PARTITION BY LIST (department) (
-- Partition for employees in the 'Sales' department
PARTITION p_sales VALUES IN ('Sales'),
-- Partition for employees in the 'HR' department
PARTITION p_hr VALUES IN ('HR'),
-- Partition for employees in the 'IT' department
PARTITION p_it VALUES IN ('IT')
);
3. Hash Partitioning
Hash partitioning involves applying a hash function to a column value, and the result determines the partition into which a row is placed. This method is useful for evenly distributing data when the specific ranges or lists are not applicable.
Example:
CREATE TABLE users (
id INT,
username VARCHAR(100)
)
-- Partition the table using a hash-based partitioning strategy
-- The 'id' column is used as the partitioning key
-- The table will be divided into 4 partitions for better performance
PARTITION BY HASH(id) PARTITIONS 4;4. Key Partitioning
Key partitioning is a variation of hash partitioning that uses MySQL’s internal function to determine the partition, providing a more balanced distribution in some cases.
Example:
CREATE TABLE orders (
order_id INT,
product_name VARCHAR(100)
)
PARTITION BY KEY(order_id) PARTITIONS 5;
Benefits of Partitioning
Improved Query Performance: By reducing the amount of data scanned during queries, partitioning can lead to faster response times.
Easier Maintenance: Large tables can be more easily managed, backed up, or archived when broken into partitions.
Efficient Data Management: Partitioning allows for data to be managed based on lifecycle policies, such as dropping old partitions to remove obsolete data.
What Is Data Sharding in MySQL?
Sharding involves splitting a database into smaller, independent databases, known as shards, that can be distributed across multiple servers. Unlike partitioning, which occurs at the table level within a single database instance, sharding distributes entire databases across multiple nodes. This approach is essential for horizontal scaling in very large applications.
Sharding typically requires application-level logic to manage the distribution of data across shards. MySQL doesn’t natively support sharding out-of-the-box, but it can be implemented using various techniques and tools.
1. Application-Level Sharding
In this method, the application is responsible for determining the appropriate shard for each piece of data. It uses a shard key, often a user ID or another unique identifier, to direct queries to the correct shard.
Example:
def get_shard(user_id):
shard_number = user_id % number_of_shards
return f"database_shard_{shard_number}"
# Querying the correct shard
shard_db = get_shard(12345)
connection = connect_to_database(shard_db)Here:
Function get_shard(user_id): This function determines which database shard to use for a given user ID.
- shard_number = user_id % number_of_shards: Calculates the shard number by taking the remainder of the user ID divided by the total number of shards. This evenly distributes users across the available shards.
- return f”database_shard_{shard_number}”: Constructs the name of the database shard based on the calculated shard number.
Querying the Correct Shard:
- shard_db = get_shard(12345): Calls the get_shard function to determine the shard for user ID 12345.
- connection = connect_to_database(shard_db): Establishes a connection to the specified database shard.
2. Proxy-Based Sharding
A proxy layer sits between the application and the database shards, directing traffic to the appropriate shard based on the query. Tools like ProxySQL and Vitess are popular choices for this method.
Vitess is an open-source project that provides a scalable MySQL cluster management solution and supports sharding at the proxy level.
3. Database Middleware
Middleware solutions handle sharding by providing an abstraction layer that manages data distribution and query routing. This approach can simplify the application code but may introduce additional complexity and latency.
Example Middleware Tools: Citus for PostgreSQL, TiDB for MySQL compatibility.
Benefits of Sharding
Scalability: Sharding enables horizontal scaling by distributing data across multiple servers, allowing for the handling of larger datasets and more concurrent users.
Fault Isolation: By distributing data across shards, the impact of a failure is limited to a specific shard, improving overall system resilience.
Geographic Distribution: Sharding can distribute data closer to users, reducing latency and improving access speed.
What Is the Difference Between Partitioning and Sharding in MySQL?
While both partitioning and sharding aim to improve performance and scalability, they have distinct characteristics and use cases.
Size and Complexity
Partitioning is recommended when dealing with large tables within a single database instance where improved performance and manageability are needed.
On the other hand, you should opt for sharding when the entire database needs to be distributed across multiple servers to accommodate massive data volumes or high user loads.
Infrastructure
Partitioning can typically be handled within existing infrastructure, while sharding may require additional resources and complex configuration.
Application Requirements
You should consider sharding for applications with significant data distribution needs or that require multi-regional deployments. However, you can use partitioning for more straightforward scenarios where data can be logically separated within a single database.
Here’s a table to demonstrate the key differences between data partitioning and sharding.
| Aspect | Data Partitioning | Data Sharding |
| Purpose | Divide data within a single database system into smaller subsets (partitions) for better management. | Distribute data across multiple servers or nodes to enhance scalability and improve throughput. |
| Implementation | Typically confined to a single database instance. | Involves distributing data across various databases or servers. |
| Query Efficiency | Enhances query efficiency by reducing disk I/O operations. | Improves performance by distributing load among servers. |
| Use Cases | Useful for optimizing data management within a database. | Ideal for large databases with high traffic to improve scalability. |
| Example Scenario | Splitting a large table into smaller partitions based on a specific column (e.g., date ranges). | Distributing customer data across different shards based on a shard key. |
Frequently Asked Questions
Is sharding only for SQL?
Sharding is a fundamental characteristic of NoSQL databases, specifically engineered to manage massive datasets by distributing data across multiple servers for enhanced scalability and availability.
When to partition vs shard?
Sharding is primarily employed to distribute the workload across multiple servers for improved scalability, while partitioning optimizes data management and performance within a single database instance.
Conclusion
Data partitioning and sharding are powerful strategies for managing large datasets and improving database performance in MySQL. Partitioning allows for breaking down tables into manageable pieces, while sharding provides the ability to distribute data across multiple servers.