Kubernetes Node Autoscaling with Karpenter
When setting up an EKS cluster, it’s typical to utilize EC2 node groups to allocate the computing resources for the Kubernetes cluster. The issue arises when needing to adjust these node groups dynamically to match the computing demands of the pods running on the cluster.
While HPA (Horizontal Pod Autoscaling) can scale the number of pods based on demand, the number of EC2 nodes remains static. That is where Karpenter comes in.
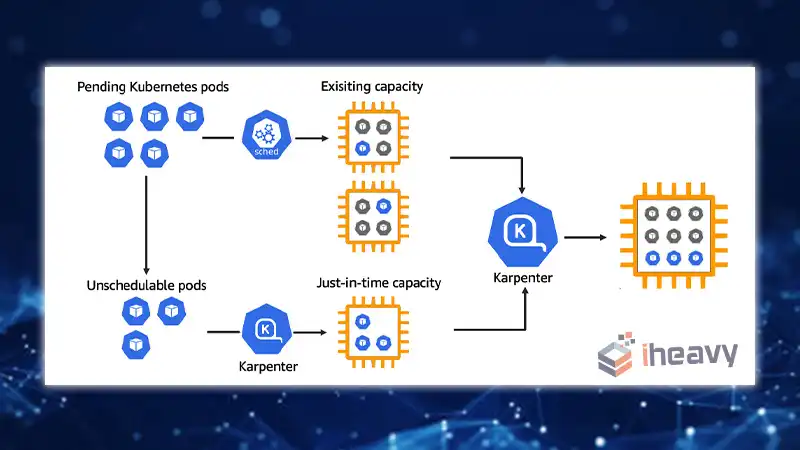
How Karpenter Works
With Karpenter integrated into your Kubernetes cluster, it continuously monitors the aggregate resource requests of unscheduled pods. Based on this observation, Karpenter autonomously makes decisions to launch new nodes or terminate existing ones, minimizing scheduling latencies and infrastructure costs.
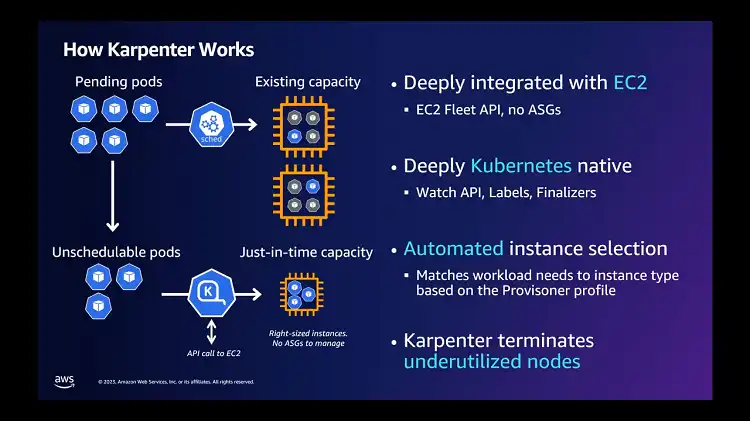
This seamless orchestration is achieved by leveraging events within the Kubernetes cluster and sending commands to the underlying AWS compute service, such as Amazon EC2.
Getting Started with Karpenter on AWS
Deploying Karpenter in your Kubernetes cluster is a straightforward process. Start by ensuring that you have available compute capacity and then install Karpenter using the provided Helm charts available in the public repository. Additionally, ensure that Karpenter has the necessary permissions to provision compute resources in your AWS environment.
To illustrate a quick start with Karpenter on Amazon EKS, follow these steps:
Setting Up Tools: Install the AWS Command Line Interface (CLI), kubectl, eksctl, and Helm.
Cluster Creation: Use eksctl to create a Kubernetes cluster. Below is an example configuration file for creating a basic cluster:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eks-karpenter-demo
region: us-east-1
version: "1.20"
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2
name: eks-kapenter-demo-ng
desiredCapacity: 1
minSize: 1
maxSize: 5
Execute the following command to create the cluster:
eksctl create cluster -f cluster.yamlConfiguring Karpenter
Karpenter’s flexibility allows it to run seamlessly on various Kubernetes environments, including self-managed node groups, managed node groups, or AWS Fargate. To configure Karpenter, you’ll need to set up necessary AWS Identity and Access Management (IAM) resources using provided templates and install the Helm chart to deploy Karpenter into your cluster.
helm repo add karpenter https://charts.karpenter.sh
helm repo update
helm upgrade --install --skip-crds karpenter karpenter/karpenter --namespace karpenter \
--create-namespace --set serviceAccount.create=false --version 0.5.0 \
--set controller.clusterName=eks-karpenter-demo \
--set controller.clusterEndpoint=$(aws eks describe-cluster --name eks-karpenter-demo --query "cluster.endpoint" --output json) \
--waitLeveraging Karpenter Provisioners
Karpenter provisioners allow you to customize the behavior of Karpenter within your cluster. By default, Karpenter automatically discovers node properties, such as instance types, zones, architectures, and purchase types. However, you can customize these properties as per your requirements.
Below is an example of creating a default provisioner:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.large", "m5.2xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-east-1a", "us-east-1b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
provider:
instanceProfile: KarpenterNodeInstanceProfile-eks-karpenter-demo
ttlSecondsAfterEmpty: 30Observing Karpenter in Action
Once Karpenter is active in your cluster, it automatically provisions nodes in response to pod scheduling demands. You can observe Karpenter’s actions by creating pods using a deployment and monitoring the provisioning process.
kubectl create deployment inflate \
--image=public.ecr.aws/eks-distro/kubernetes/pause:3.2 \
--requests.cpu=1
To scale the deployment and view Karpenter's logs, execute the following commands:
kubectl scale deployment inflate --replicas 10
kubectl logs -f -n karpenter $(kubectl get pods -n karpenter -l karpenter=controller -o name)Frequently Asked Questions
Can I use Karpenter with other cloud providers besides AWS?
Yes, Karpenter is designed to work with any Kubernetes cluster running on any environment, including major cloud providers and on-premises setups.
Does Karpenter support accelerated computing instances?
Karpenter seamlessly integrates with accelerated computing instances, making it ideal for applications requiring rapid provisioning of diverse compute resources, such as machine learning model training or complex simulations.
Conclusion
Karpenter revolutionizes Kubernetes node autoscaling, offering a seamless solution for managing compute resources in AWS environments. By automating node provisioning and optimization, Karpenter enhances application availability, reduces infrastructure costs, and ensures efficient resource utilization.