SQL Server Maintenance Plan Best Practices | Detailed Guideline
SQL Server maintenance plans are a critical component of any SQL Server environment. They help to ensure that your database is healthy and performing at its best.
For SQL Server maintenance plans, including best practices for creating, executing, and monitoring them the whole article would be a great handnote. We will also discuss some common troubleshooting tip
The Critical Importance of Maintenance Plans
Routine maintenance is crucial for peak SQL Server performance and reliability. Tasks like backups, integrity checks, indexing, and statistics management help ensure databases are optimized, stable, and protected. Automating these tasks using maintenance plans provides consistency while freeing up admin time.
However, developing optimized plans requires thoughtful design and testing. Poorly configured maintenance plans can strain resources and cause disruptions. This guide covers best practices to help craft maintenance plans that keep your SQL environment humming.
Best Practices for Maintaining SQL Server
When creating and executing SQL Server maintenance plans, there are a few best practices to keep in mind:
- Monitoring Performance for a Healthy Baseline
- Checking Vital Signs: Daily monitoring provides early warning of brewing issues before they escalate into outages. Capture baseline metrics like CPU, memory, and disk usage, I/O patterns, query response times, blocking, and deadlocks. Know what “normal” looks like.
- Being Proactive: Analyze trends over time to catch problems arising gradually before they reach critical thresholds. Sudden spikes in activity or resource usage often indicate trouble. Tune queries, add capacity, and restart services based on monitoring insights.
- Using Appropriate Tools: Built-in tools like Performance Monitor and Dynamic Management Views provide low-overhead monitoring. Third-party tools like SolarWinds Database Performance Analyzer add deeper insights with less effort. Proper tools prevent information overload.
- Review Regularly: Designate time weekly or monthly to review reports and logs with a broad perspective. Monitoring data is useless if not reviewed regularly. Turn monitoring into actionable improvement.
- Backup Strategies for Disaster Recovery
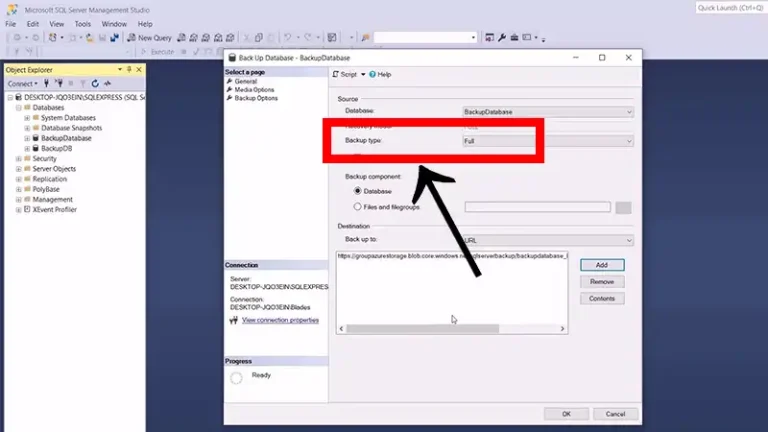
- Types of Backups: Full weekly backup captures the entire database. Differential daily backup records change since full backup. Transaction log backups every 2-4 hours for point-in-time restore.
- Test Restores: Validate backup integrity regularly by restoring copies to test servers. Verify databases are intact and undamaged. Identify flaws in the backup process before disaster strikes.
- Backup Retention: Balance recovery needs with storage capacity. Keep weekly backups for 1-2 months. Monthly backups for 6-12 months. Yearly backups for 3-5 years. Test restores from each tier.
- Encryption: Encrypt backups to protect from unauthorized access when stored offline or offsite. Manage keys carefully for recovery.
- Compression: Use backup compression to reduce storage footprints and speed up backups. Test to ensure compression doesn’t adversely affect backup/restore performance.
- Maintaining Indexes and Statistics
- Index Rebuilding: Rebuild indexes weekly or when fragmentation hits 30%. Keep indexes optimized. Rebuild during maintenance windows to minimize disruption.
- Statistics Updates: Update statistics weekly or daily if heavy data changes. Statistics power query optimization. Rebuild indexes first before updating associated statistics.
- Partitioned Objects: When rebuilding indexes or updating stats on large partitioned objects, target individual partitions where possible to minimize disruption.
- Intelligent Reorganization: Avoid blindly reorganizing indexes by default. Assess fragmentation trends over time and reorganize only when fragmentation approaches 30%.
- Guarding Data Integrity
- Consistency Checks: Run DBCC CHECKDB weekly to validate database structural integrity. CHECKTABLE can isolate table corruptions.
- Error Logging: Report errors to logs for follow-up. Restore from backup immediately if corruption is found.
- Page Verification: Enable Page Verify Checksums to detect torn page corruption issues.
- Extended Properties: Use extended properties to mark databases that require higher integrity checks like financial data. Check critical databases more frequently.
- Monitoring Disk Usage
- Proactive Adds: Monitor space usage and add storage before databases become overloaded. Enable auto-growth for files to expand smoothly.
- Transaction Logs: Keep a sharp eye on transaction log file growth and avoid running out of space. Enlarge log files proactively when nearing capacity.
- Capacity Planning: Right-size storage for workload needs. Budget for growth using historical usage patterns. Avoid allocating vastly excessive unused space.
- Regular Cleanup: Remove obsolete backup files, truncate logs, and archive unneeded data to free up space. Shrink overly large files when necessary.
- Optimizing Maintenance Windows
- Low-Impact Hours: Schedule maintenance during periods of low user activity like nights and weekends. Define time windows wisely to minimize performance impact.
- Allow Sufficient Time: Tune the schedule based on task durations and dependencies. A backup must finish before verification can start. Build in buffer time.
- Resource Usage: Stagger resource-intensive operations like rebuilding indexes and statistics updates to avoid resource contention.
- Business Cycles: Factor in monthly closing, year-end processing, audit periods, etc., and pause or reschedule maintenance to avoid conflicts.
- Automation and Alerting
- Configuring Alerts: Set up alerts for failed operations, corruption errors, performance issues, etc. Alerts inform of problems in real-time.
- Email Notifications: Automatically email results of maintenance executions to administrators for quick notification.
- Logging: Log maintenance plan execution details like failures, warnings, and information to facilitate troubleshooting.
- Leveraging Automation: Use tools like Policy Based Management to apply standardized maintenance configurations automatically across SQL instances.
- Testing and Validation
- Testing in Lower Environments: Test maintenance plans thoroughly in dev and test environments first before deploying to production. Identify potential issues.
- Validating Backups: Confirm backup integrity by restoring copies and running DBCC CHECKDB. Verify mission-critical data is intact.
- Monitoring Executions: After deploying to production, monitor live executions to ensure proper completion in the scheduled windows.
- Tuning and Adjustment: Continuously fine-tune plans based on runtimes, failures, and resource usage patterns. Adjust as needs evolve.
FAQs – Frequently Asked Questions and Answers
- How often should database integrity checks be performed?
Answer: It’s recommended to perform integrity checks at least weekly. Critical databases should be checked more frequently – daily or several times a week.
- What index fragmentation level signals a need for rebuild?
Answer: If index fragmentation hits 30% or greater, a rebuild should be performed to restore optimal performance. Below 30%, reorganize may be sufficient based on usage patterns.
- What steps validate the integrity of database backups?
Answer: To validate backups, restore copies to an isolated test server and execute integrity checks using DBCC CHECKDB. Verify no corruption errors are reported and that key data samples are present.
To Conclude
SQL Server maintenance plans that incorporate backups, integrity checks, performance monitoring, and index/statistics management following best practices are essential for peak database performance and reliability.
While developing effective plans takes forethought and testing, diligence pays off in keeping mission-critical SQL environments running smoothly.